
Microsoft Teams ayuda a los estudiantes y profesionales de todo el mundo a seguir las reuniones en línea con subtítulos en vivo generados por IA y transcripción en tiempo real, características que están recibiendo un impulso de las tecnologías de computación de IA de NVIDIA para el entrenamiento y el Servidor de Inferencia NVIDIA Triton para la inferencia de modelos de reconocimiento del habla.
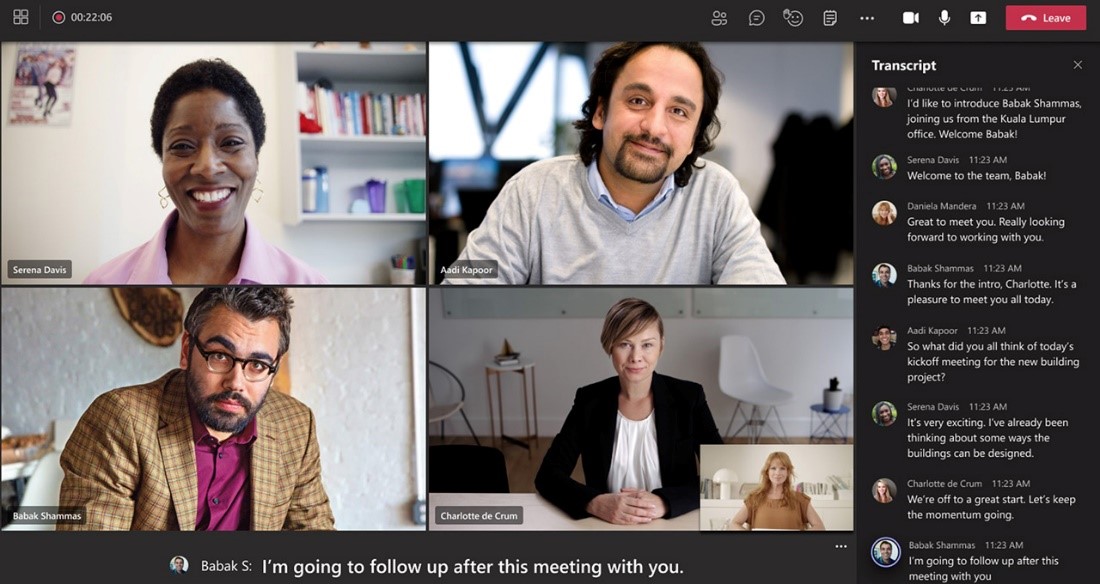
Teams permite la comunicación y la colaboración en todo el mundo para casi 250 millones de usuarios activos mensuales. Las conversaciones de los equipos se subtitulan y transcriben en 28 idiomas mediante Microsoft Azure Cognitive Services, un proceso que pronto ejecutará la inferencia de red neuronal crucial que requiere mucha potencia de computación en las GPUs de NVIDIA.
La función de subtítulos en vivo ayuda a los asistentes a seguir la conversación en tiempo real, mientras que las funciones de transcripción ayudan a los asistentes a ofrecer una manera fácil de retomar más tarde las buenas ideas o ponerse al día con las reuniones perdidas.
Los subtítulos en tiempo real pueden ser especialmente útiles para los asistentes sordos o con problemas de audición, o que no son hablantes nativos del idioma utilizado en una reunión.
Teams utiliza Cognitive Services para optimizar los modelos de reconocimiento de voz mediante el software de servicio de inferencia de código abierto NVIDIA Triton.
Triton permite a Cognitive Services admitir modelos de lenguaje altamente avanzados, a fin de ofrecer resultados de voz a texto altamente precisos y personalizados en tiempo real, con una latencia muy baja. La adopción de Triton garantiza que las GPUs de NVIDIA que ejecutan estos modelos de voz a texto se utilicen en todo su potencial, lo que reduce los costos al brindar a los clientes un mayor rendimiento utilizando menos recursos computacionales.
La tecnología de reconocimiento de voz subyacente está disponible como API en Cognitive Services. Los desarrolladores pueden usarlo para personalizar y ejecutar sus propias aplicaciones para la transcripción de llamadas de servicio al cliente, controles de hogares inteligentes o asistentes de IA para socorristas.
La IA se Aferra a Cada Palabra.
Las transcripciones y subtítulos de los equipos, generados por Cognitive Services, convierten el habla en texto e identifican al hablante de cada declaración. El modelo reconoce la jerga, los nombres y otros contextos de reunión para mejorar la precisión de los subtítulos.
“Los modelos de IA como estos son increíblemente complejos, ya que requieren decenas de millones de parámetros de redes neuronales para ofrecer resultados precisos en docenas de idiomas diferentes”, dijo Shalendra Chhabra, Gerente Principal de PM para el equipo Dispositivos, Reuniones y Llamadas de Teams de Microsoft. “Cuanto más grande es un modelo, más difícil es ejecutarlo de manera rentable en tiempo real”.
El uso de las GPUs de NVIDIA y el software Triton ayuda a Microsoft a lograr una alta precisión con potentes redes neuronales sin sacrificar la baja latencia: la conversión de habla a texto aún se transmite en tiempo real.
Y, cuando la transcripción está habilitada, las personas pueden ponerse al día fácilmente con el material perdido después de que una reunión haya concluido.
La Trifecta de Características de Triton Impulsan la Eficiencia.
NVIDIA Triton ayuda a optimizar la implementación de modelos de IA y desbloquear la inferencia de alto rendimiento. Los usuarios pueden incluso desarrollar backends personalizados adaptados a sus aplicaciones. Algunas de las capacidades clave del software que permiten que los subtítulos y las características de transcripción de Microsoft Teams se escalen a un mayor número de reuniones y usuarios incluyen:
- Inferencia de transmisión: NVIDIA y Azure Cognitive Services trabajaron juntos para personalizar la aplicación de habla a texto con una novedosa característica de inferencia de transmisión con estado que puede realizar un seguimiento del contexto del habla anterior para mejorar la precisión de los subtítulos sensibles a la latencia.
- Procesamiento dinámico por lotes: El tamaño del lote es la cantidad de muestras de entrada que una red neuronal procesa simultáneamente. Con el procesamiento dinámico por lotes de Triton, las solicitudes de inferencia única se combinan automáticamente para formar un lote, utilizando mejor los recursos de la GPUs sin afectar la latencia del modelo.
- Ejecución simultánea de modelos: Los subtítulos y las transcripciones en tiempo real requieren ejecutar varios modelos de deep learning a la vez. Triton permite a los desarrolladores hacer esto simultáneamente en una sola GPU, incluso con modelos que utilizan diferentes frameworks de deep learning.
Comienza a usar las funciones de habla a texto en tus aplicaciones con Azure Cognitive Services, y obtén más información sobre cómo el software del Servidor de Inferencia NVIDIA Triton ayuda a los equipos a implementar modelos de IA a escala.
Mira el discurso destacado de GTC a cargo de Jensen Huang, fundador y CEO de NVIDIA, que se transmitirá en vivo el 9 de noviembre y estará disponible en repetición.

